There may be multiple reasons why your website is not showing up in Google, e.g.
- new website
- no incoming backlinks
- poor quality content
- crawling has not been permitted
- indexation has not been allowed etc
Firstly, to quickly check if your webpage is on Google use one of these two methods. Note: the 1st method is preferred as it’s much more reliable.
- Use the URL inspection tool within your Google Search Console account
- Navigate to GSC -> URL inspection
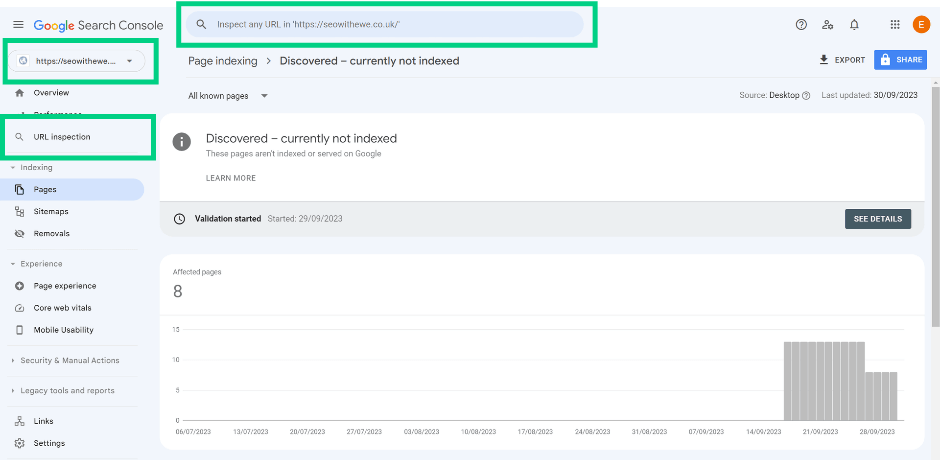
Insert the URL you want to investigate into the ‘Inspect any URL in https://yourdomain.com/ field’ and review the outcome.
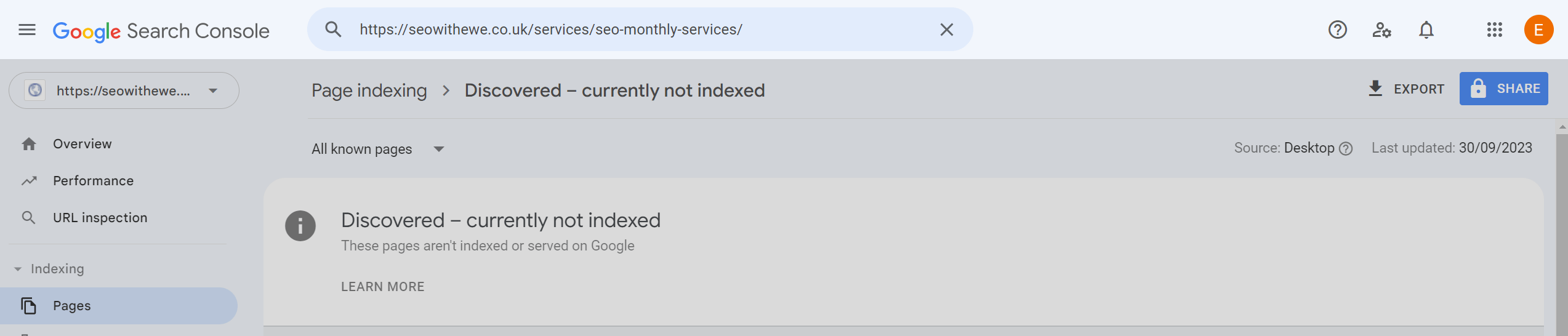
Google will provide you with information whether your page is on Google or not, and any issues that may prevent indexation
or
- Use: “site:” syntax in a incognito window
- site:domain or path to see which pages within your domain Google indexed
- site:yourdomain/service pets vaccinations – search for subjects covered by your page
- site:yourdomain.com/exact-url to see if an exact page on your site id within Google’s index
Once you established that your page has not been indexed by Google, investigate the root cause of the issue.
How do search engines work?
Before a webpage can appear in the search engine results page (SERP) multiple criteria must be met:
- Firstly, Google needs to be aware of your page existing on the web.
Google bots can discover pages by following links from external domains (backlinks) or you can use Google Search Console to submit your URLs to Google. If you want to learn how to set up Google Search Console and submit your domain or URL prefix, follow my step-by-step GSC set-up guide.
- Secondly, your page needs to be indexable (robots meta tag, data-nosnippet, and X-robots-tag need to permit Google to index the page/content).
- Additionally, it should provide high-quality content to users, which should be fast and easily accessible across all devices.
In short, search engines
- Discover
- Crawl
- Render (if a page relies on JavaScript)
- Index
- Rank.
In order for a page to show up on Google, it needs to successfully pass each stage before appearing in SERP.
16 most common indexation issues and how to solve them
Server error (5xx)
When Google tried accessing your URL it wasn’t able to because:
- The request timed out, or
- Your site was busy
And Google had to abandon the request.
Recommendation:
- Audit the host status within Crawl Stats report (GSC – Select property – Settings – Crawl Stats) to establish if Google is reporting site availability issues that can be confirmed and fixed. If the host status is red, review the availability details for robots.txt availability, DNS resolution, and host connectivity.
- Reduce excessive page loading for dynamic page requests by keeping parameter lists short and using them sparingly.
- Ensure your site’s hosting server is not down, overloaded, or misconfigured. If the issue persists, you may want to increase your site’s ability to handle traffic.
- Ensure Google is not blocked via a DNS configuration.
- Crawling and indexing control may have been implemented incorrectly.
Redirect error
Google was not able to index the page because of a faulty redirect which may have been caused by:
- A redirect chain that was too long (more than 5 redirects)
- A redirect loop (Page A redirects to Page B and Page B redirects to Page A)
- A redirect URL that exceeded the max URL length
- A bad or empty URL in the redirect chain
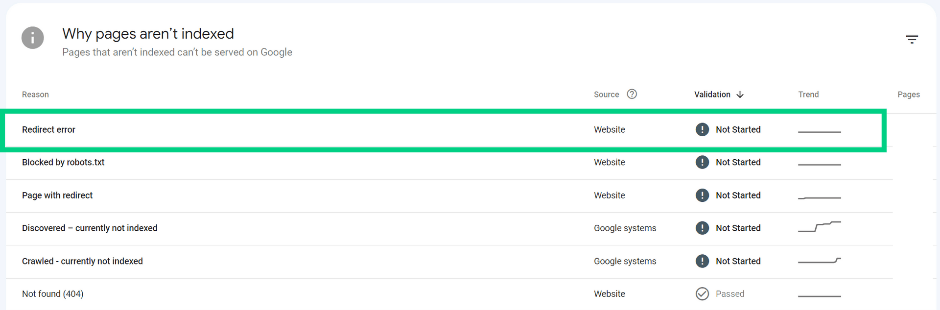
Recommendation:
Use Lighthouse to troubleshoot the issue and resolve it accordingly.
URL blocked by robots.txt
The page was blocked by your site’s robots.txt file. You can use robots.txt testing tools:
- GSC robots testing tool for verified properties
or
- Robots.txt validator and testing tool by Merkle if you don’t have access to GSC
to investigate further. Bear in mind that a page blocked from crawling can still be indexed if Google is able to gather other information about this page without loading it.
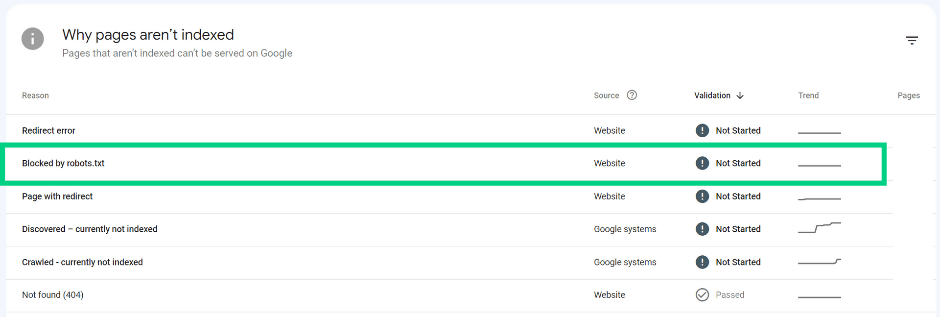
Recommendation:
Make sure that the robots.txt configuration is correct. If not, and the page should be crawled by Google, update robots.txt file accordingly.
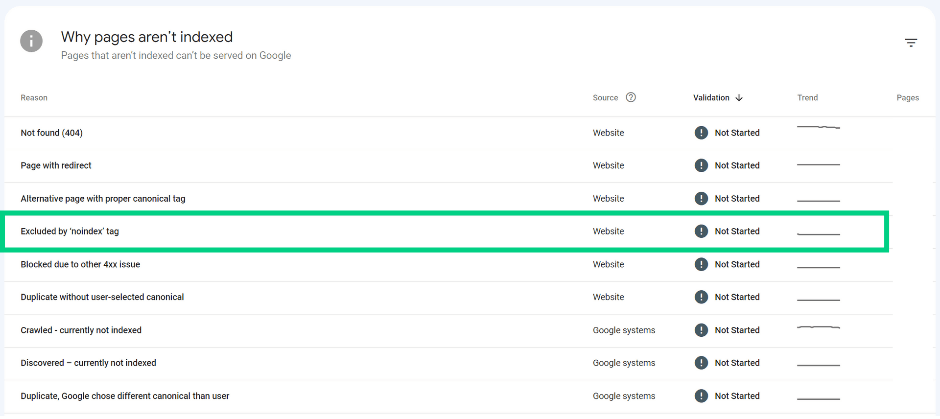
URL marked ‘noindex’ (Excluded by ‘noindex’ tag)
When crawling the page, Google encountered the ‘noindex’ directive which prevents it from indexing it.
Recommendation:
If the page with ‘noindex’ tag was not meant to be indexed, no further action is required. If the page is supposed to appear in SERP, remove the ‘noindex’ tag. Investigate the issue:
- Use the inspection tool in GSC ‘Inspect URL’
- Navigate to Coverage > Indexing > Indexing allowed? report to confirm that the ‘noindex’ tag is preventing indexing. Example?
Verify if the ‘noindex’ tag exists in the live version of the page:
- Test live URL
- Navigate to Availability > Indexing > Indexing allowed? to verify if the ‘noindex’ directive is still present. If the ‘noindex’ tag has already been removed, you can ‘Request indexing’ to ask Google to index the page.
If the ‘noindex’ tag is still present, remove the tag or the HTTP header to allow Google to index the page.
Soft 404 error
The page request returns a ‘soft’ 404 response. It returns an ‘error page’ for the users, but not a 404 HTTP response code.
Recommendation:
If the page is an error page, ensure the returned response code is correct (404) or add more content to the page to send stronger signals to Google that the page is not a 404 page. Evaluate how Google sees the page, run a live URL inspection test and use the ‘View tested page’ to preview a screenshot of how Google renders the page.
Blocked due to unauthorized request (401)
Google is not able to access the page because the authorisation request has failed or hasn’t been provided.
Recommendation:
If you want Google to be able to index the page, remove the authorisation request or allow Googlebot to access your page by verifying its identity.
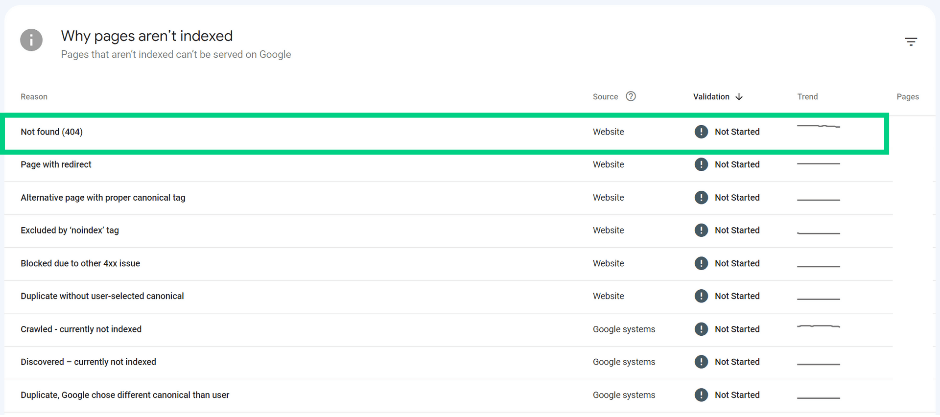
Not found (404)
Page returns a 404 status code. If the page has been removed without any replacement, it might necessarily not be a problem.
Recommendation:
If the 404 page has been moved, ensure a 301 redirect has been set up to direct Googlebot and users to the new location.
Blocked due to access forbidden (403)
The access to the page has not been granted, despite the user agent providing credentials. Googlebot never provides credentials and causes your server to return 403 error incorrectly, resulting in the given page not being indexed.
Recommendation:
If you want Googlebot to index the page:
- admit non-signed-in users or
- allow Googlebot requests without authentication.
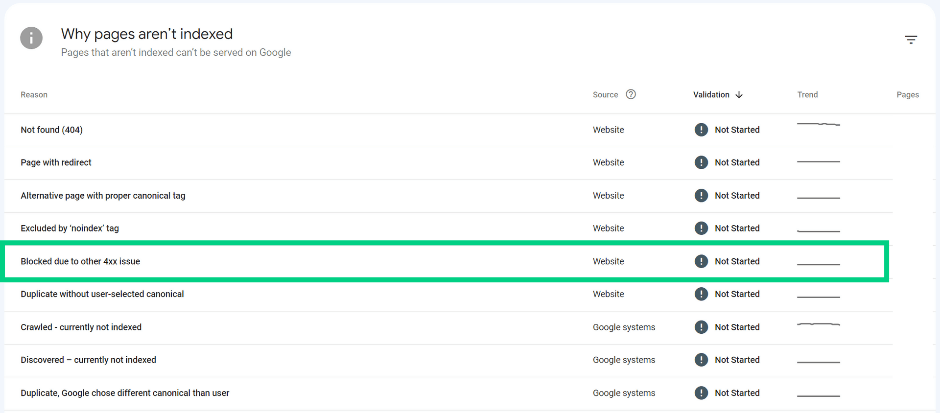
URL blocked due to other 4xx issue
The server encountered a 4xx error (not 401, 403, 404).
Recommendation:
Use URL inspection tool to investigate and troubleshoot the issue.
Blocked by page removal tool
The page is blocked by a URL removal request submitted by someone who manages your property in Google Search Console or by an approved request from a site visitor. A removal request is in force for around 90 days and Google may try indexing this page once the time is up.
Recommendation:
If you don’t want the page to be indexed, use the most suitable option to prevent indexation:
- Implement the ‘noindex’ tag
- Require authorization for the page, or
- Remove the page
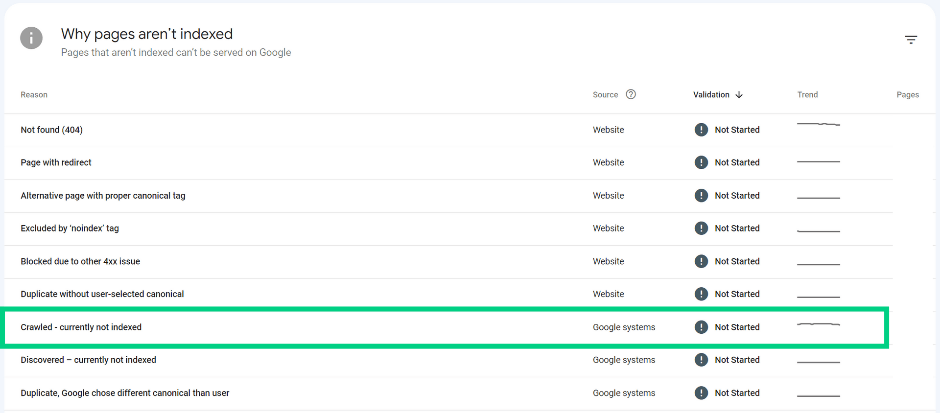
Crawled – currently not indexed
Google is aware that the page exists but hasn’t indexed it yet.
Recommendation:
If you’d like the page to be indexed ensure it follows SEO best practices.
Discovered – currently not indexed
Google has found the page but it hasn’t been crawled yet probably due to the potential of overloading the site. To prevent overloading the site, Google rescheduled the crawl.
Recommendation:
If only a small number of pages within your domain has been affected by ‘Discovered – currently not indexed’, use the manual indexation option. Bear in mind that you can add around 10 URLs per day to the priority crawl queue. Monitor indexation status of submitted URLs, if they haven’t been indexed troubleshoot the issue. Indexation may be affected by:
- Crawl budget issues
- Duplicate content issues
- Internal nofollow links
- Lack of internal incoming links
- Poor quality of content.
Once you establish the root cause of the issue, rectify it before requesting indexing.
Alternative page with proper canonical tag
If you’re using the rel=alternate tag to inform the crawler about alternate versions of a page, such as an accelerated mobile page (AMP). The message may be triggered when the canonical version of a chosen page has been indexed and not the page itself, such as:
- an AMP page with a desktop canonical
- a mobile version of a desktop canonical
- a desktop version of a mobile canonical.
Recommendation:
Review the URL(s) to ensure that this is the appropriate behaviour and that they should not be indexed.
Duplicate without user-selected canonical
If Google thinks that a page is a duplicate of another it may highlight it in Google Search Console as ‘Duplicate without user-selected canonical’. Sometimes Google marks pages as duplicate even if they are not exact duplicates. Before troubleshooting the issue, make the issue really affects your page. Check which page has been chosen by Google as the canonical version of the page via the Inspect Tool in GSC.
Recommendation:
- Canonical link chosen by Google and your preferred version of the page are uniform
If the canonical chosen by Google is the preferred version of the page, you don’t need to take action. It’s good practice to implement a canonical on each page of your website.
- Canonical link chosen by Google and your preferred version of the page are not uniform
Mark the correct canonical for your page
- Page’s content is not a duplicate
Make sure the content served across pages is unique and differs significantly from each other. Google may also choose a different canonical to the one implemented by the user, if:
- the canonical link has not been implemented properly, <most common canonical link implementation issues> -> separate article
- Google believes there’s a better suited URL that could be served as a canonical
- other ‘hints’ (e.g. sitemap.xml inclusion, incoming internal links) that indicate which page is the preferred version.
Duplicate, Google chose different canonical than user
This might happen if the URL in question has been marked as a canonical for another page, but Google thinks that a different URL is more suitable to be the master version of that page.
If the self-referencing canonical has been ignored by Google, make sure that your page’s content is unique and has a sufficient number of incoming internal links. If a canonical URL pointing to a different page has been ignored by Google, make sure that the pages’ content differs significantly from each other and is individually unique to increase the chances of Google following the user-declared canonical. If applicable, update the canonical URL to point to a more relevant page. If your site is available through non-secure and secure versions (HTTP and HTTPS), or with or without www, make sure to implement a redirect to clearly indicate the preferred version.
Recommendation:
- Use the Inspection Tool within GSC to establish Google-selected canonical.
- Review user-declared canonical under Page indexing > User-declared canonical in GSC.
- Check Google-selected and user-declared canonical in your browser.
This error means that Google thinks that the tested page isn’t a duplicate of the user-declared canonical. Instead, Google thinks that the tested page is a duplicate of the Google-selected canonical.
- If the Google-selected canonical is the tested page, then Google thinks that the tested page isn’t similar to any other pages.
- If the user-declared canonical is not similar to the current page, then Google won’t ever choose that URL as canonical. A duplicate page must be similar to the canonical. (That’s what duplicate means.)
- If the page is not a duplicated version of another, make sure the content served across those pages is unique and differs significantly from each other and offers unique value to the end user.
Make sure that your canonical links have been implemented correctly to reduce the chances of canonical-related issues appearing in Google Search Console, increase the chances of correct pages being indexed, and prevent ranking anomalies.
Page with redirect
A page has been redirected to another page and returns 3xx status code. This page won’t be indexed as it does not return 200 status code. The target URL of the redirect might or might not be indexed, depending on the target URL.
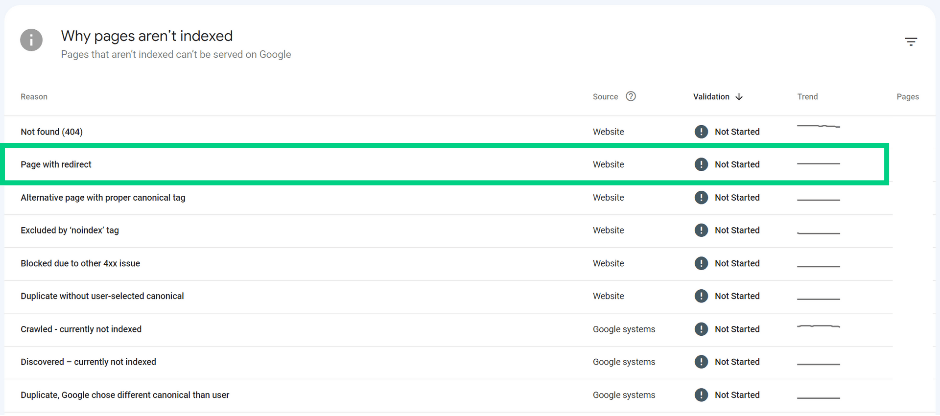
Recommendation:
Page returning a 3xx code won’t be indexed. Inspect the target URL to establish any indexation issues. Is the target URL indexed? If not, investigate.
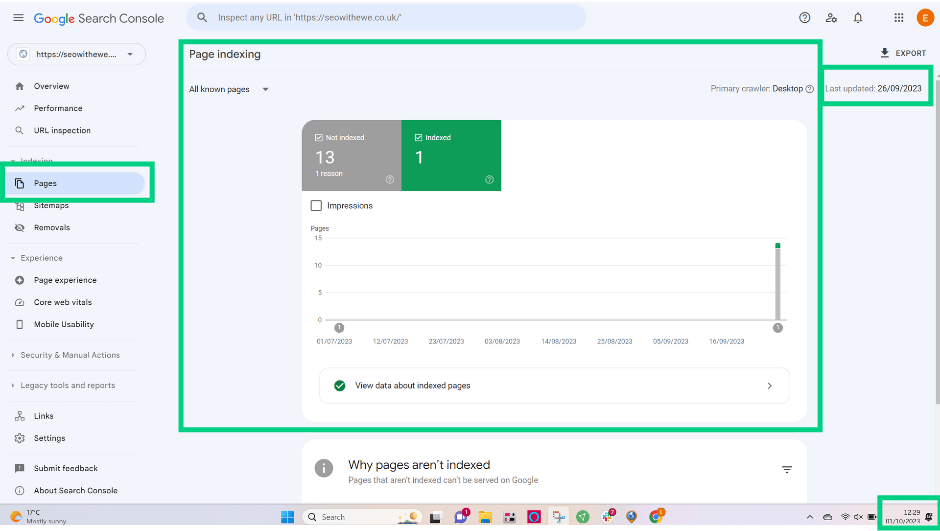
Page indexing report
If you’re using the Page indexing report in GSC to audit your indexation issues, be aware that the data may not be up-to-date. If your website hasn’t been crawled for a while (5 days delay in the example below), use the ‘Test live URL’ to troubleshoot potential issues.
Summary
To increase indexability of your website, make sure that:
- your website receives backlinks, ideally from reputable domains
- your domain has been verified in Google Search Console and that you’ve submitted your sitemap.xml via the Indexing > Sitemaps option in GSC.
- your webpages return 200 status code
- your webpages can be crawled
- your webpages can be rendered
- your webpages can be indexed.
Identify which stage
- Discovery
- Crawling
- Rendering
- Indexing
prevents your page(s) from appearing in Google and act accordingly. Alternatively, reach out and I’ll happily investigate the root causes of indexing issues and advise about possible viable solutions.
